
BLR Neighborhood Explorer
One place to decide where to live in Bengaluru — before signing a lease
Who
People relocating to Bengaluru — new joiners, transferees, anyone choosing a neighborhood in a city they don't know yet.
Why
Choosing where to live in an unfamiliar city is a high-stakes decision made with terrible information. Renters juggle five browser tabs of outdated listings, paywalled livability reports, and word-of-mouth — then commit to a 12-month lease anyway. The job to be done: compare neighborhoods on what actually matters (rent, commute, amenities, weather) in one trustworthy view.
What
A map-first comparison engine that scores 100+ Bengaluru neighborhoods on rent, livability, amenities, and commute — refreshed nightly from live sources, free and open.
- —Interactive map of 100+ scored neighborhoods — click any area to drill into rentals, amenities, and scores
- —Transparent livability scoring across schools, hospitals, supermarkets, and commute zones — you can see why an area scores what it does
- —Live rental listings, weather, and commute estimates aggregated from 4+ sources
- —Nightly automated data refresh — nothing on the map is stale
Impact
→Peaked at around 400 visitors in its launch week, and friends used it to shortlist neighborhoods when relocating to Bengaluru.
How — architecture
live sources
nightly cron
PostgreSQL
REST
frontend
Built with
Inclusive Certification Coach
Certification prep that adapts to how you learn — built for employees the standard training path leaves behind
Who
Employees with accessibility needs (neurodivergent, cognitive, low-vision) preparing for certifications — plus their managers, who need progress visibility without violating the learner's privacy.
Why
Enterprise certification training treats every learner identically. For employees with accessibility needs, that means plans that ignore cognitive load, calendars with no realistic study time, multiple-choice tests that measure recognition instead of understanding, and forgetting curves nobody accounts for. Certifications stall — and the learner gets blamed.
What
An 8-agent AI coach that builds accommodation-aware study plans around real calendars, grades understanding through teach-back instead of multiple choice, and shares progress with managers only on the learner's terms.
- —Day-by-day study plans that respect your accommodations and real calendar gaps — with honest pushback when a deadline is infeasible
- —Practice with cited questions, or explain concepts in your own words (teach-back)
- —Spaced refreshers timed to your forgetting curve
- —You control exactly what your manager sees — redaction enforced in code
- —Screen-reader-friendly narrator for every output
Impact
How — architecture
Streamlit + narrator
plan
bounded loop
advance / loop / escalate
consent-redacted
Built with
Fitness Progress Coach
An AI coach that knows your training history — inside the app you already use daily
Who
Lifters following a structured programme who want coaching feedback grounded in their own history, not generic fitness-app advice.
Why
Fitness apps fail at two moments: logging (tedious forms kill the habit) and coaching (generic tips that ignore what you did last week). The user need is a coach with memory — one that references your actual last four sessions, spots your plateau, and tells you what to change. No mainstream app connects logging friction and contextual feedback.
What
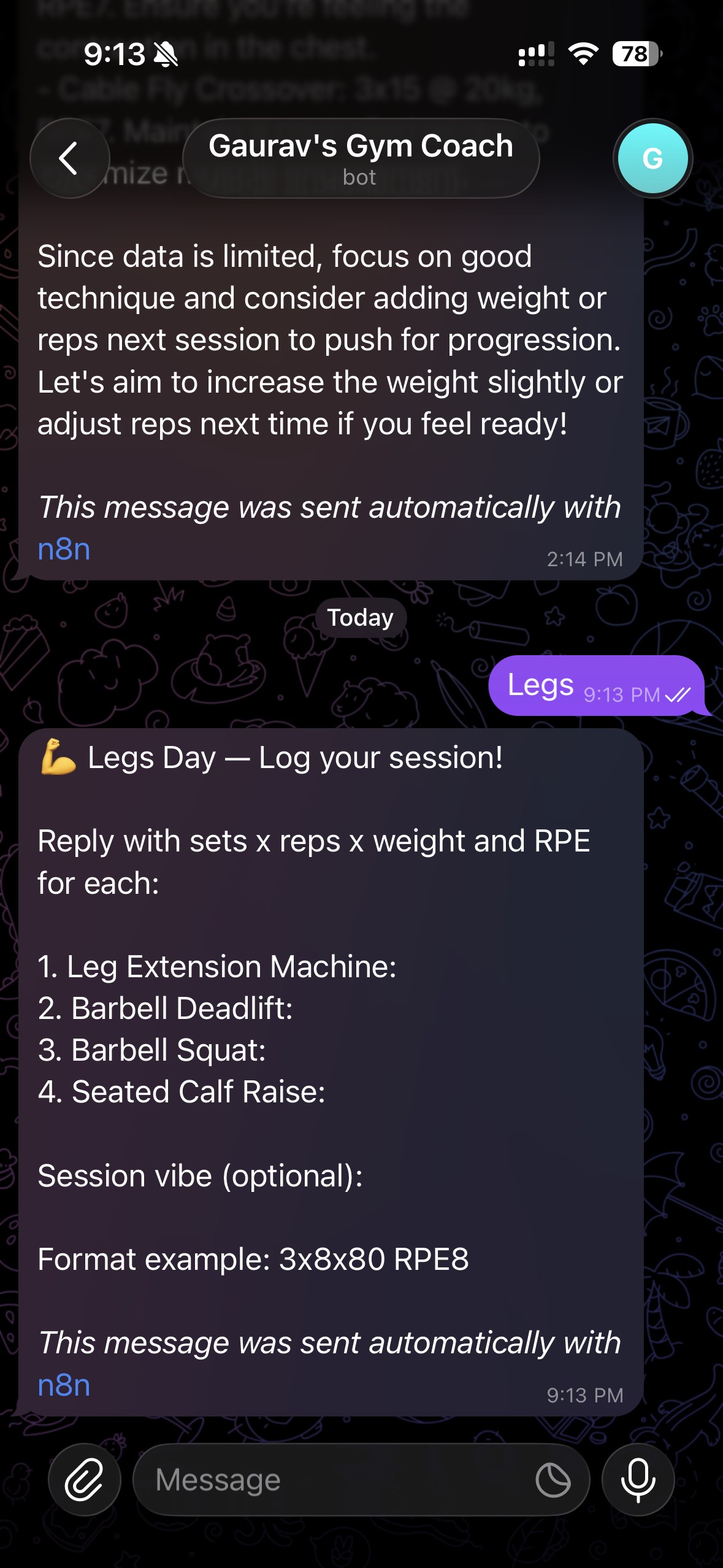
A Telegram coach: text one keyword to get your workout template, reply with your numbers, and get feedback grounded in your last four sessions — plateaus and PRs included.
- —Text a keyword (chest · back · shoulder · legs) and get your workout template instantly
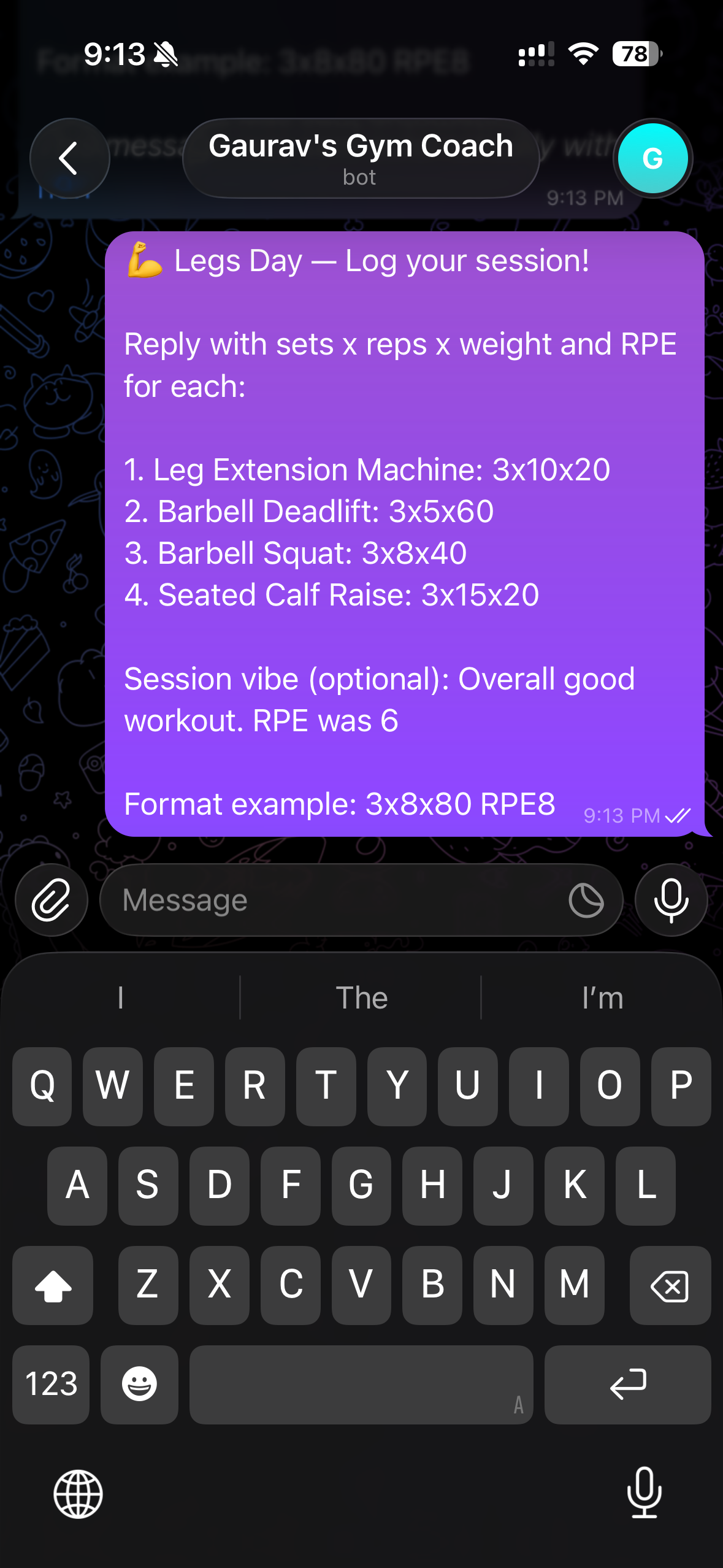
- —Reply with sets, reps, weight, RPE — logged automatically, one row per exercise
- —Coaching feedback that references your last 4 sessions — plateaus and PRs flagged
 →
→ →
→
Impact
→I use it daily to log workouts and get coaching grounded in my own training history.
How — architecture
trigger
webhook + switch
keyword / workout
extract + log
GPT-4o-mini
feedback
Built with
For Job Hunt
Give job seekers their 2–3 hours a day back
Who
Job seekers in India hunting HR/talent roles across fragmented job boards — starting with one very motivated user: me.
Why
Job hunting in India means manually checking Naukri, LinkedIn, Indeed, SmartRecruiters, and Workday every single day. That's 2–3 hours of repetitive scanning before a single application is written — and the cost of missing a fresh posting is real. The job to be done: see only the relevant new openings, twice a day, with zero effort.
What
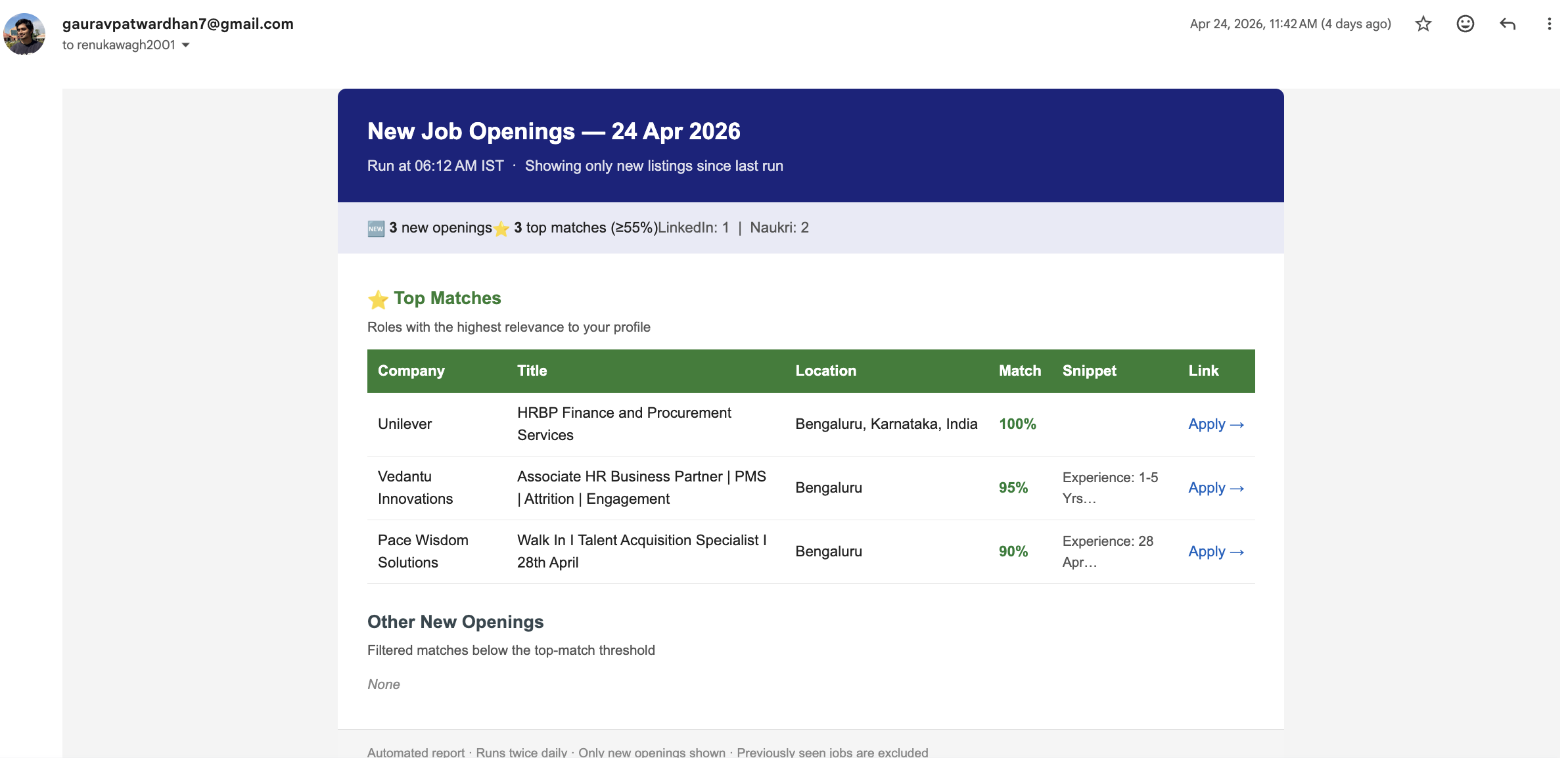
An automated scout that scrapes 5+ job boards, deduplicates and ranks openings against your resume, and lands a color-coded digest in your inbox twice a day.
- —Curated job digest in your inbox at 9 AM and 6 PM IST — no boards to check
- —Openings ranked by fit: resume keyword match blended with GPT semantic scoring
- —Color-coded relevance for 10-second triage; duplicates removed across a 3-day window
Impact
How — architecture
job boards
scraping
Supabase + GPT-3.5
ranked by relevance
9 AM + 6 PM IST
Built with